TL;DR
-
3시간 안에 NestJS + TypeORM + PostgreSQL로 수강신청 API를 구현했다.
-
비관적 락으로 동시성을 제어했지만, Course에만 락을 걸고 Student에는 걸지 않아서 학점 제한이 뚫리는 버그를 놓쳤다.
-
구현 관점의 세션 2개로는 다양한 문제의 가능성을 찾지 못한다는 걸 배웠다.
시험 개요
| 항목 | 내용 |
|---|---|
| 시험 | 무신사 AI Native Engineer 2차 코딩테스트 |
| 일시 | 2026-02-08 (일) 15:00 ~ 18:00 (3시간) |
| 과제 | 대학교 수강신청 REST API 서버 구현 |
| 핵심 | "정원 1명 남은 강좌에 100명이 동시 신청해도, 정확히 1명만 성공해야 합니다" |
| 제출 | 시간 내 최종 commit/push |
1차가 알고리즘 문제풀이였다면, 2차는 성격이 완전히 다르다.
3시간 안에 백엔드 서비스를 처음부터 설계하고 구현해야 한다.
기획팀의 요구사항 문서는 의도적으로 불친절하게 주어지고, 명시되지 않은 부분은 스스로 판단해서 문서화해야 한다.
그리고 무엇보다 이 시험의 핵심은 AI를 어떻게 활용하는가였다.
도구 선택
Claude Code를 쓴 이유
무신사에서 Codex를 무료로 제공해줬지만, 3시간이라는 제한 안에서 새 도구를 익히는 리스크를 감수할 이유가 없었다.
Claude Code는 평소에 쓰던 도구라 작업 흐름이 이미 잡혀 있었고, 특히 CLAUDE.md 기반의 컨텍스트 관리, @ 링크로 필요한 문서만 선택적으로 불러오는 기능, 그리고 터미널 네이티브 환경이 이번 시험의 2개 세션 분리 전략을 실행하는 데 적합했다.
처음 추천 받은 기술 스택

Claude Code와 PROBLEM.md를 읽으며 논의하던 중 가장 먼저 추천 받은 기술 스택이다.
하지만 결국 작업을 시작할 때는 이 중 하나도 선택하지 않고 다른 도구들로 진행하게 됐다.
이에 대한 내용을 더 풀어보고자 한다.
NestJS
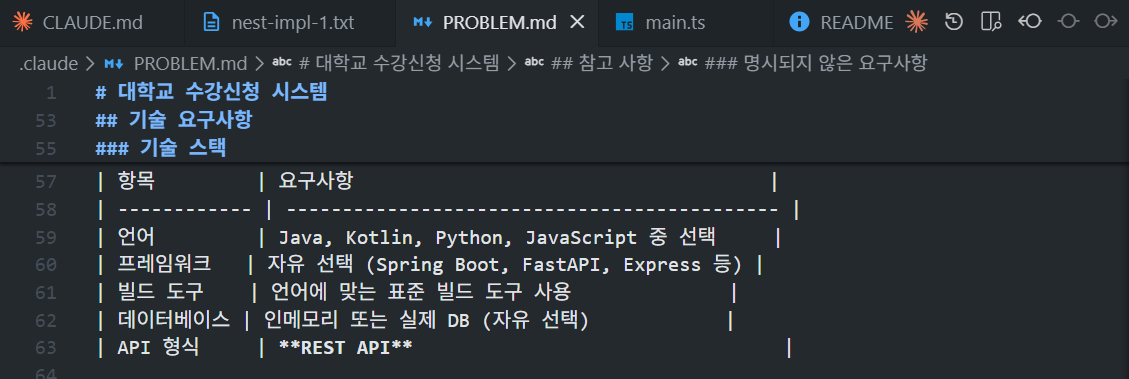
평소에는 주어진 상황에 따라 프레임워크를 골라서 쓰려고 하는 편인데 학생이다보니 적은 인원, 예산 등을 중요하게 고려해야헸다.
그렇다보니 가볍고, 자유롭고, 학습곡선이 완만하며 유연한 프레임워크를 사용하게 되는 경향이 있었다.
결국 최근에는 주로 Express, Fastify, FastAPI를 선택했던 것 같다.
하지만 Claude Code와 작업하기 시작하면서 새로운 프레임워크의 학습 곡선이 많이 낮아졌다.
공식 문서를 MCP로 참조하며 작업하니 처음 쓰는 프레임워크도 버그 없이 사용할 수 있다.
덕분에 "익숙 vs 최적" 사이에서 후자를 선택하는 게 부담이 줄었다.
그리고 제일 중요한건 언어만 선택지에서 벗어나지 않는다면 프레임워크가 자유 선택이었다.
Node.js의 개발 경험을 선호하는 나에게는 기회가 찾아온 것이다.
백엔드 개발자를 준비하는 대부분이 스프링을 사용하기에 포기했던 NestJS를 사용할 기회가.
NestJS를 고른 이유는 Module/Controller/Provider 구조가 엄격하게 정해져 있기 때문이다.
Spring처럼 규격이 명확하면서도 TypeScript 기반이라 보일러플레이트가 적다.
3시간이라는 제한 시간 안에서 빠르게 구조를 잡으면서도 AI와 협업할 때 일관된 코드가 나올 거라 판단했다.
실제로 AI가 생성한 코드를 리뷰하기도 훨씬 쉬웠다.
개인적으로는 다양한 기술을 사용해보고 싶은 마음이 크기 때문에 써보고 싶었던 이유도 있다.
공고에도 "새로운 기술을 시도하는 것을 두려워하지 않는 태도를 기다립니다"라고 적혀 있기도 했고.
PostgreSQL
동시성 제어와 데이터 정합성이 과제의 핵심이었기 때문에, DB 레벨에서 확실하게 잡고 싶었다.
DB 락을 선택한 이유는 트랜잭션과 락의 생명주기가 일치하기 때문이다.
애플리케이션 레벨 락(인메모리 mutex 등)을 쓰면 락 획득과 트랜잭션이 별개 레이어가 되어, 예외 발생 시 락 해제를 직접 관리해야 한다.
DB의 SELECT FOR UPDATE는 트랜잭션이 끝나면 자동으로 해제되므로 검증과 락의 생명주기가 일치하고, scale-out 시에도 별도 변경 없이 동작한다는 부가적 이점도 있다.
SQLite 인메모리라는 더 가벼운 선택지도 있었지만, 실제 프로덕션과 거리가 먼 선택이라고 판단했다.
PostgreSQL을 선택한 건 TypeORM 공식 문서와 예시가 PostgreSQL 기준으로 작성된 경우가 많아서다.
MCP로 문서를 참조하며 작업할 때 예시 코드를 그대로 적용하기 편했다.
Docker
Docker Compose를 선택한 가장 큰 이유는 평가자의 테스트 편의성이었다.
PROBLEM.md에 "평가자가 빌드 및 실행에 실패하면 이후 평가가 어렵습니다"라고 명시되어 있었다.
docker compose up --build 한 줄이면 PostgreSQL 컨테이너 + 앱 컨테이너 + 시드 데이터 생성까지 전부 완료된다.
평가자 PC에 Node.js나 PostgreSQL이 설치되어 있지 않아도 Docker만 있으면 된다.
환경 차이로 인한 "제 컴퓨터에서는 되는데요" 문제를 원천 차단할 수 있다.
재미있는 건, Claude가 처음에 Java + Spring Boot + H2를 제안했다는 것이다.
내가 "NestJS는 어렵나?"라고 물었고, 다시 SQLite를 추천했을 때 "도커로 다른 DB 실행하면 안 됨?"이라고 물어서 최종적으로 PostgreSQL에 도달했다.
AI와의 협업 방식
2개 세션 전략
시험 동안 Claude Code 세션을 2개로 분리해서 운영했다:
-
메인 세션: 전체 계획 수립, 문서 작성, 코드 리뷰, git 관리
-
구현 세션: 계획 문서를 기반으로 실제 코드 구현
메인 세션이 큰 그림을 잡고 있으면서, 구현 세션의 결과물을 검증하는 구조였다.
구현 세션에서 커밋이 올라오면 메인 세션에서 빌드/테스트를 돌리고, 문서와 구현이 일치하는지 확인했다.
CLAUDE.md로 AI 행동 제어
auto accept를 쓰지 않기 때문에 (모든 도구 호출을 직접 승인), AI의 작업 흐름이 자주 끊기면 속도가 느려진다.
그래서 CLAUDE.md에 코딩 원칙, TDD 방식, 커밋 컨벤션, 테스트 우선순위 등을 상세하게 적어서 AI가 매번 물어보지 않고도 올바른 방향으로 작업하게 만들었다.
태스크가 완료될 때마다 CLAUDE.md의 구현 상태 체크리스트를 업데이트해서, 어느 세션에서든 현재 진행 상황을 파악할 수 있게 했다.
MCP로 공식 문서 참조
Claude Code에 Context7 MCP를 연결해서 라이브러리 공식 문서를 실시간으로 참조할 수 있게 했다.
Context7의 덕을 본 순간이 여럿 있었지만 하나만 꼽아보았다.
e2e 테스트에서 테스트 간 데이터를 정리하기 위해 AI가 repository.delete({})를 작성했는데, 테스트를 실행하니 다음과 같은 에러가 발생했다.
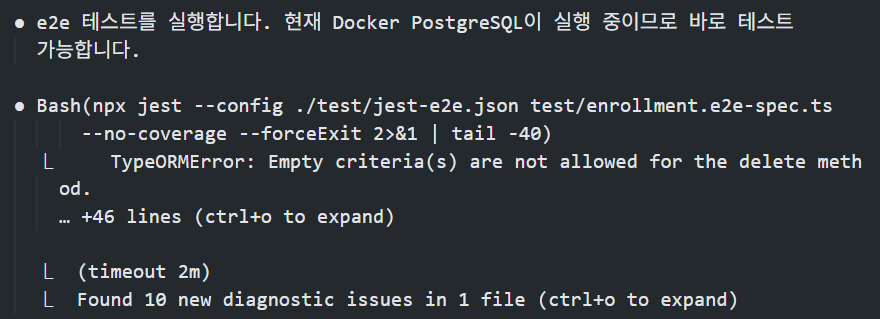
필자는 TypeORM을 사용해본 적이 없기에 깊게 개입할 수 없었고, AI가 혼자 해결하려고 시도하기에 interrupt를 발생시켰다.
Claude Code가 해당 라이브러리의 명확한 사용법을 알지 못하기에 발생하는 문제라고 판단했고 바로 Context7을 사용하라고 지시했다.
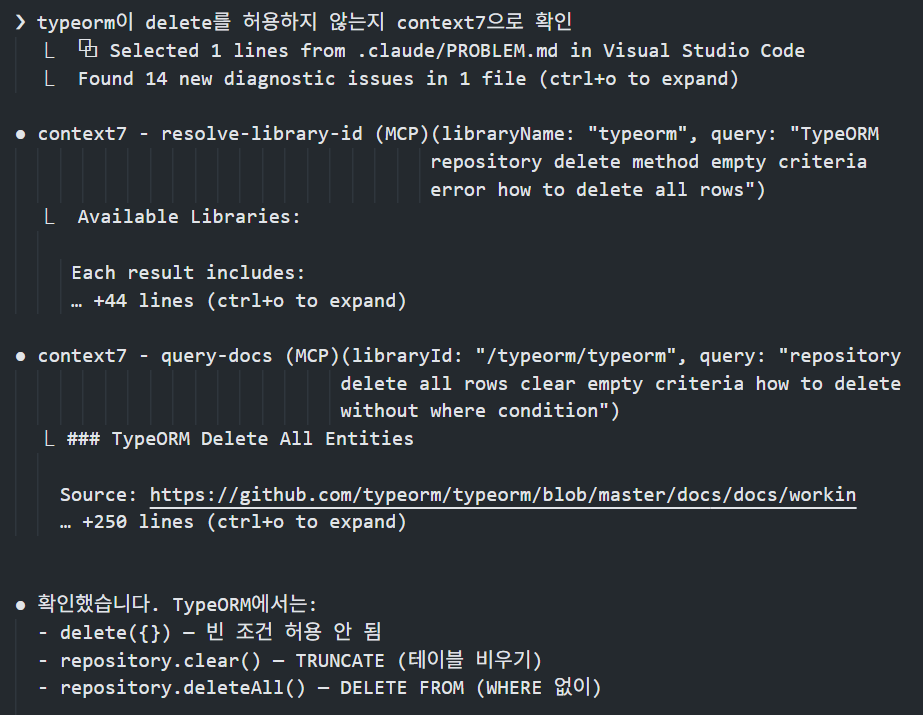
AI가 Context7으로 TypeORM 공식 문서를 조회하고, repository.clear()(TRUNCATE)가 올바른 API라는 걸 확인해서 즉시 해결했다.
AI가 추측으로 해결하려 했으면 몇 번 더 시행착오를 겪었을 것이다.
공식 문서를 직접 참조하게 하는 게 시간도 아끼고 복잡한 방식으로 해결하지 않기에 코드 가독성도 올라간다.
인간의 역할: 방향 설정자 + 브레이크
대화 로그를 돌아보면, 내가 한 일이 반복적으로 나타난다:
AI의 제안을 수정하거나 거부:-
Claude가 Java + Spring Boot를 제안 → NestJS로 변경
-
Claude가 SQLite를 추천 → PostgreSQL (Docker)로 변경
-
Claude가 불필요한 문서(ARCHITECTURE.md)를 작성하려 함 → "PROBLEM.md에서 요구하는 문서만"
-
구현으로 달려가려는 AI를 여러 번 멈추고 문서부터 정리하게 함
-
TDD를 건너뛰고 코드를 한꺼번에 작성하려는 AI를 제지: "우리 TDD 기반으로 작업해야돼. CLAUDE.md 다시 확인해봐."
-
TypeORM API를 모를 때 추측으로 해결하려는 AI에게 context7(공식 문서 조회) 사용을 강제
-
커밋 단위가 너무 클 때 "이미 만든 걸 다 커밋하기보다는, 정확히 작업한 파일들만 커밋"
AI가 코드 작성 속도를 담당하고, 나는 방향과 품질을 관리하는 구조였다.
핵심 기술 결정: 동시성 제어
비관적 락 전략
수강신청의 핵심 흐름:
트랜잭션 시작
→ Student 조회 (존재 확인)
→ Course 조회 + FOR UPDATE (비관적 락)
→ 정원 확인
→ 중복 신청 확인
→ 학점 확인 (18학점 제한)
→ 시간충돌 확인
→ Enrollment INSERT + enrolled 카운트 증가
→ 커밋 (락 해제)Course row에 FOR UPDATE 락을 걸면, 같은 강좌에 대한 동시 요청이 직렬화된다.
정원이 1명 남았을 때 100명이 동시에 신청해도 한 명씩 순차적으로 처리되므로 정확히 1명만 성공한다.
낙관적 락(version column + retry)도 고려했지만, 수강신청은 인기 강좌에 수백 명이 동시에 몰리는 고충돌 도메인이다.
충돌할 때마다 정원·학점·시간충돌 검증을 처음부터 재시도해야 하므로 낙관적 락은 오히려 비효율적이다.
SERIALIZABLE isolation level은 DB 레벨에서 정합성을 보장하지만, serialization failure 시 재시도 로직을 애플리케이션에서 직접 구현해야 하고 3시간 안에 안정적으로 만들기엔 리스크가 컸다.
비관적 락은 구현이 단순하면서도 이 도메인의 충돌 패턴에 가장 잘 맞는 선택이었다.
LEFT JOIN + FOR UPDATE 함정
구현 중에 실제로 부딪힌 이슈가 있었다.
TypeORM에서 relations 옵션과 lock을 동시에 쓰면, 내부적으로 LEFT JOIN ... FOR UPDATE가 생성되는데, PostgreSQL은 이를 허용하지 않는다:
QueryFailedError: FOR UPDATE cannot be applied to the nullable side of an outer joinDocker에서 처음 실행했을 때 500 에러가 나서 로그를 확인해보니 이 에러였다.
relations를 빼고 락 쿼리에서는 Course 데이터만 가져오는 것으로 해결했다.
주석으로도 남겨뒀다:
// 강좌 조회 + FOR UPDATE 비관적 락 (relations 없이 락 — LEFT JOIN과 FOR UPDATE 비호환)
const course = await queryRunner.manager.findOne(Course, {
where: { id: dto.courseId },
lock: { mode: "pessimistic_write" },
// relations: ['professor', 'department'],
});그리고, 놓친 것: Student 락 누락
이 과제에서 가장 큰 아쉬움이다.현재 코드는 Course에만 비관적 락을 건다.
이 말은, 서로 다른 강좌에 대한 요청은 병렬로 실행된다는 뜻이다.
동일 학생이 서로 다른 강좌 2개를 동시에 신청하면 어떻게 될까:
학생 A (현재 15학점), 동시에 강좌 X(3학점)와 강좌 Y(3학점) 신청
요청1 (강좌 X) 요청2 (강좌 Y)
───────────── ─────────────
BEGIN BEGIN
Student 조회 (락 없음) Student 조회 (락 없음)
Course X FOR UPDATE Course Y FOR UPDATE ← 서로 다른 row라 대기 없음
학점 확인: 15+3=18 ≤ 18 ✓ 학점 확인: 15+3=18 ≤ 18 ✓ ← 요청1의 INSERT가 아직 미커밋
INSERT enrollment INSERT enrollment
COMMIT COMMIT
결과: 학생 A = 21학점 (18학점 초과!)시간충돌도 같은 원리로 뚫린다.
월요일 1교시 강좌 두 개를 동시에 신청하면 둘 다 "기존 수강 내역에 월 1교시 없음"으로 판단한다.
해결 방법: Student에도 비관적 락을 건다.
// Student도 FOR UPDATE
const student = await queryRunner.manager.findOne(Student, {
where: { id: dto.studentId },
lock: { mode: "pessimistic_write" },
});같은 학생의 동시 요청이 Student 락에서 직렬화되므로, 학점/시간충돌 검증이 정확해진다.
데드락 방지를 위해 항상 Student → Course 순서로 락을 잡아야 한다.
다만 Student 락을 추가하면 같은 학생의 모든 수강신청이 직렬화되어 throughput이 떨어진다.
하지만 현실적으로 한 학생이 밀리초 단위로 여러 강좌를 동시에 신청하는 경우는 드물기 때문에, 정합성을 위해 감수할 만한 trade-off라고 판단했다.
데드락 방지를 위해서는 모든 수강신청 트랜잭션에서 반드시 Student → Course 순서로 락을 획득하도록 서비스 레이어에서 강제해야 한다.
수강취소에서도 enrolled 감소 시 같은 원리가 적용되므로, 동일한 락 순서를 유지해야 한다.
왜 놓쳤는가: PROBLEM.md의 기획팀 메모가 "정원 1명 남은 강좌에 100명이 동시 신청"이라는 시나리오에 집중시켰다.
e2e 테스트도 이 시나리오만 검증했고, "같은 학생이 다른 강좌를 동시에 신청"하는 케이스는 떠올리지 못했다.
돌아보면 이건 세션 설계의 한계이기도 했다.
메인 세션과 구현 세션이 같은 맥락을 공유하고 있었기 때문에, 둘 다 같은 프레임에 갇혔다.
만약 적대적 검증 역할의 세션을 별도로 뒀다면 — "이 동시성 제어를 어떻게 우회할 수 있을까?"라는 관점으로 코드를 분석하는 역할 — 이 버그를 시험 중에 잡았을 것이다.
3시간의 시간 배분
실제 흐름
| 시간대 | 작업 |
|---|---|
| 15:00~15:30 | 요구사항 분석, 기술 스택 결정, CLAUDE.md 작성 |
| 15:30~16:00 | REQUIREMENTS.md, API.md, README.md 작성 |
| 16:00~16:30 | 인프라 + 엔티티 + 조회 API + TDD로 핵심 로직 구현 |
| 16:30~17:00 | Seed 데이터, Docker 통합, FOR UPDATE 버그 수정 |
| 17:00~17:30 | e2e 테스트 (동시성 100명, 학점, 시간충돌, 중복, 취소) |
| 17:30~17:50 | 테스트 보강, Swagger UI, DB 인덱스, 로깅 추가 |
| 17:50~18:00 | CLAUDE.md 루트 복사, 최종 merge + push |
두 가지 핵심 판단
1. 처음 30분을 코드 없이 문서에 투자했다.3시간 중 30분이면 큰 비중이다.
하지만 문서가 없으면 AI가 매번 방향을 물어보고, 내가 매번 답해야 한다.
문서를 먼저 작성하고 CLAUDE.md에 링크해두면, 이후 구현 세션에서 AI가 독립적으로 작업할 수 있다.
다만 돌아보면 30분도 부족했다.
메인 세션 하나로 문서를 작성하고 바로 구현에 들어갔는데, 별도의 검토 세션으로 계획을 점검하는 시간을 가졌다면 더 견고한 설계가 나왔을 것이다.
Student 락 누락도 이 단계에서 잡을 수 있었다.
"빨리 구현해야 한다"는 압박이 오히려 전체 품질을 낮췄다.
핵심 기능 구현 전에 1차 merge로 main에 "동작하는 베이스라인"을 확보했다.
PROBLEM.md에
완성하지 못했더라도 반드시 제출하세요. 부분 구현도 평가 대상입니다
라고 적혀 있었기 때문에, 최악의 경우에도 제출 가능한 상태를 유지하는 게 중요했다.
아쉬운 점
1. Student 락 누락 (위에서 상세히 다룸)
가장 큰 아쉬움. 적대적 검증 세션의 부재.
2. TDD가 부분적으로만 적용됨
schedule.util과 enrollment.service는 Red → Green → Refactor를 깔끔하게 지켰다.
하지만 조회 API(Student, Course, Professor)는 코드를 먼저 작성하고 테스트를 나중에 붙였다.
시간 압박 때문이었지만, 나중에 테스트 커버리지가 낮아서 헐레벌떡 테스트를 추가한 느낌이 남았다.
CLAUDE.md에 TDD 원칙을 명시해놓고 본인이 지키지 않은 셈이라 더 아쉽다.
3. synchronize: true
TypeORM의 synchronize: true는 앱 실행 시 엔티티 정의에 맞게 DB 스키마를 자동으로 변경한다.
개발 환경에서는 편리하지만, 프로덕션에서는 데이터 손실 위험이 있다.
NODE_ENV에 따라 분기하는 처리를 했어야 했는데 미처 생각하지 못했다.
4. 검증 순서
검증 순서도 개선이 필요하다.
현재는 Course에 락을 건 후 정원 → 중복 → 학점 → 시간충돌 순으로 검증하는데, 두 가지 문제가 있다.
-
이미 신청한 강좌를 다시 신청했는데 "정원이 가득 찼습니다"라고 응답하면 사용자가 혼란스럽다.
-
어차피 실패할 요청(중복 신청, 학점 초과)이 락을 점유하는 동안 다른 요청이 불필요하게 대기한다.
중복·학점·시간충돌 확인은 락 없이도 가능하므로, 락 획득 전에 사전 필터로 먼저 처리하면 실패 요청을 빠르게 걸러내고 락 보유 시간을 줄일 수 있다.
다만 사전 필터는 빠른 실패를 위한 최적화이지 검증의 대체가 아니다.
사전 확인 시점과 락 획득 시점 사이에 다른 트랜잭션이 상태를 바꿀 수 있으므로, 정합성 검증은 락 안에서 반드시 재수행해야 한다.
면접을 앞두고
이번 시험에서 가장 명확하게 확인한 건, AI는 방향 없이 두면 불필요한 곳에서 토큰을 소모한다는 점이다.
실제로 시험 중 AI가 요구하지 않은 문서를 작성하려 하거나, TDD 원칙을 무시하고 코드부터 짜려는 걸 여러 번 제지했다.
AI의 속도를 활용하려면 그 속도를 어디에 쓸지 결정하는 사람이 필요하다.
동시에, 방향을 잡아주는 것만으로는 부족하다는 것도 배웠다.
메인 세션과 구현 세션이 같은 관점을 공유했기 때문에 Student 락 누락을 잡지 못했다.
방향 설정과 별개로, 그 방향을 의심하는 역할이 필요하다.
다음에 같은 상황이 온다면 세 가지를 바꿀 것이다.
-
구현 세션과 별도로 적대적 검증 세션을 둔다. "이 동시성 제어를 어떻게 우회할 수 있을까?"라는 관점의 세션이 있었다면 Student 락 누락은 시험 중에 잡을 수 있었다. 같은 도구라도 프롬프트의 관점이 다르면 다른 결과를 낸다는 걸 이번에 배웠고, 이건 검증해볼 가치가 있는 가설이다.
-
계획 단계에 시간을 더 쓴다. 30분이 아쉬웠던 게 아니라, 30분 안에서 구현 계획만 세우고 검증 계획을 세우지 않은 게 문제였다. "어떤 테스트를 통과해야 완성인가"를 먼저 정의했다면 TDD도 흐지부지되지 않았을 것이다.
-
프로덕션 체크리스트를 CLAUDE.md에 포함시킨다. synchronize:true, 검증 순서, 에러 응답 일관성 같은 것들은 매번 떠올리기 어렵지만, 체크리스트로 만들어두면 AI가 알아서 점검할 수 있다.
이번 코딩테스트는 3시간이라는 제한 안에서 내가 어떤 판단을 잘하고 어디서 놓치는지를 압축적으로 보여줬다.
Student 락 누락이라는 구체적인 실패가 없었다면 세션 설계의 한계도, 검증 계획의 부재도 깨닫지 못했을 것이다.